Pageview Time Experiment
Published on , 659 words, 3 minutes to read
My blog has a lot of content in a lot of diverse categories. In order to help me decide which kind of content I should publish next, I have created a very simple method to track pageview time and enabled it for all of my blogposts. I'll go into detail of how it works and potential risks of it below.
The high level idea is that I want to be able to know what kind of content has people's attention for the longest amount of time. I am using the time people have the page open as a particularly terrible proxy for that value. I wanted to make this data anonymous, simplistic and (reasonably) public.
How It Works
Here is how it works:
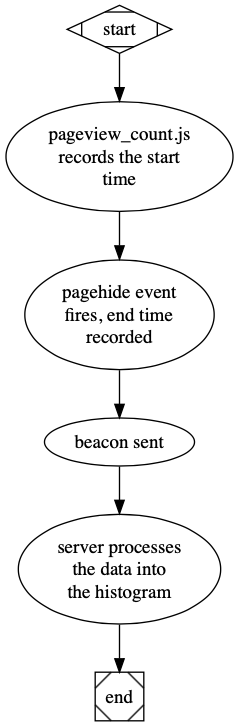
When the page is loaded, a javascript file records the start time. This then sets a pagehide handler to send a navigator beacon containing the following data:
- The path of the page being viewed
- The start time
- The end time recorded by the pagehide handler
This information is asynchronously pushed to /api/pageview-timer
and added to an in-memory prometheus histogram. These histograms can be checked at
/metrics. This data is not permanently logged.
Security Concerns
I believe this data is anonymous, simplistic and public for the following reasons:
I believe this data is anonymous because there is no way for me to correlate users to histogram entries, nor is there a way for me to view all of the raw histogram entries. This site records the bare minimum for what I need in order to make sure everything is functioning normally, and all data is stored in ephemeral in-memory containers as much as possible. This includes any logs that my service produces.
I believe this data is simplistic because it only has a start time, a stop time and the path that is being looked at. This data doesn't take into account things like people leaving a page open for hours on end idly, and that could skew the numbers. The API endpoint is also fairly unprotected, meaning that falsified data could be submitted to it easily. I think that this is okay though.
I believe this data is public because I have the percentile views of the histograms
present on /metrics. I have no reason to hide this data, and I do not
intend to use it for any moneymaking purposes (though I doubt it could be to begin
with).
I fully respect the do not track header and flag in browsers.
If pageview_timer.js detects the presence of
do not track in the browser, it stops running immediately and does not set the pagehide
handler. If that somehow fails, the server looks for the presence of the DNT header
set to 1 and instantly discards the data and replies with a 404.
Like always, if you have any questions or concerns please reach out to me. I want to ensure that I am creating useful views into how people use my blog without violating people's rights to privacy.
I intend to keep this up for at least a few weeks. If it doesn't have any practical benefit in that timespan, I will disable this and post a follow-up explaining how I believe it wasn't useful.
Thanks and be well.
EDIT 2019-10-15: browsers disable this call from the context I am using and I don't really care enough to figure out how to fix it. This experiment is over. Thank you to everyone that participated. All data will be scrubbed and a followup will be posted soon.
Facts and circumstances may have changed since publication. Please contact me before jumping to conclusions if something seems wrong or unclear.
Tags: